Kubernetes のリソース制限とその挙動確認
Kubernetes でコンテナのリソースを制限について整理し、実際の挙動を確認しました。
- 1. Kubernetes のリソース制限
- 2. 検証環境構築
- 3. 検証
- 4. 所管
- 5. 参考
1. Kubernetes のリソース制限
Kubernetes ではコンテナ単位でリソース制限が可能です。
1.1. 制限をかけられるリソース
コンテナ単位で制限をかけられるリソースは以下です。
| リソース | 単位 |
|---|---|
| CPU | 1 = 1000m = 1vCPU 例:500m(0.5 vCPU) |
| メモリ | バイト(E,P,T,G,M,K,Ei,Pi,Ti,Gi,Mi,Ki を使用可能) 例:100M ※128974848, 129e6, 129M, 123Mi はほぼ同じ値 |
| エフェメラルストレージ | バイト ※メモリと同様 |
※ デバイスプラグインを使用する事で GPU 等のリソースも制限可能(GPUのスケジューリング | Kubernetes)
1.2. 設定方法
以下のように manifest 内で spec.containers.resources.requests と spec.containers.resources.limits に値を指定します。
apiVersion: v1 kind: Pod metadata: name: sample-pod spec: containers: - name: nginx-container image: nginx resources: requests: memory: "64M" cpu: "250m" limits: memory: "128M" cpu: "500m"
1.3. requests,limits
requests と limits について整理します。
| パラメータ | 説明 |
|---|---|
| requests | ・コンテナを起動するために必要な空きリソース ・空きリソース = 割り当て可能なリソース - 割り当て済みリソース・指定した値の空きリソースが Node に無い場合はコンテナを起動できない ・実際の Node のリソース使用量は見ていない ・コンテナは requests の値を超えてリソースを使用する事ができる |
| limists | ・コンテナが使用するリソースの上限 ・指定した値の空きリソースが Node に無くてもコンテナを起動できる ・コンテナは limits の値を超えてリソースを使用する事はできない ・値を指定しない場合、Node のリソースを消費し続ける ・limits のみ指定した場合、requests は limits と同じ値が設定される ・limits を超えようとした場合の挙動 ・メモリ:OOM エラーでコンテナが強制終了する(SIGTERM は送られずに kill される) ・CPU:コンテナは終了されない(ただ CPU を使えないだけ) |
1.4. オーバーコミット
requests と limits に差があるとオーバコミットをさせる事ができます。オーバーコミットにはメリット、デメリットがあるのでメモリを例として説明します。
※ オーバーコミットとは、コンテナの limits の合計が Node のリソースより大きい事を許容する方式
割り当て可能リソース(Allocatable) が 2GB の Node には、requests 0.5GB,limits 1GB の Pod を 4 個起動できます。limits の合計が 4GB となり Node のリソースより大きいためオーバーコミットの状態です。Pod が常に多くのリソースを使うわけでは無い場合にこの構成が可能です。
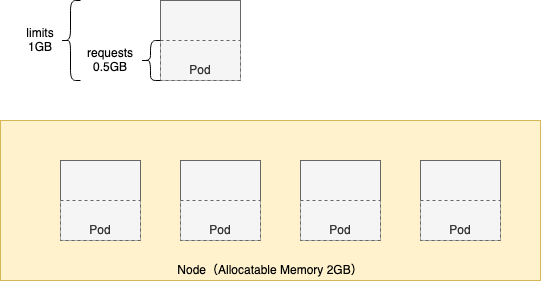
しかし、この状態で Pod の負荷が高まると Eviction Manager により最も requests を超過してリソースを使用している Pod が Evict されます。(PodPriority を設定していない場合)
※ Eviction Manager については別の記事で整理
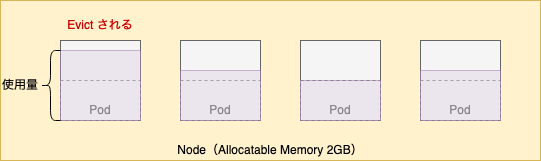
つまり、オーバコミットさせると Pod の集約率は上がりますが、Pod の稼働が不安定になる可能性があります。
逆に requests と limits を同じ値に設定すると Pod の集約率は下がりますが、Pod の稼働は安定します。
1.5. 実際にどのようにリソースを制限しているか
コンテナランタイムに Docker を使用している場合、manifest で指定した requests,limits のうち requests.memory 以外は docker のオプションに渡されてコンテナのリソースを制限します。
| パラメータ | 説明 |
|---|---|
| requests.cpu | ・コア値に変換され 1024倍された値と 2 のいずれか大きい方が docker の --cpu-shares オプションとして使用される※ --cpu-shares はコンテナに割り当てる CPU の相対値・例えば 500m を指定した場合、 --cpu-shares の値は(500 / 1000 * 1024 =) 512 となる |
| limits.cpu | ・ミリコア値に変換され 100倍された後に docker の --cpu-quota オプションとして使用される※ --cpu-quota は --cpu-period ごとに使用できる CPU 時間の合計(マイクロ秒)※ --cpu-period は Kubernetes では 100 ミリ秒で固定・例えば 1000m を指定した場合、 --cpu-quota の値は(1000 * 100 =)100000 になる(つまり 100 ミリ秒間に使用できる CPU 時間は 100000 マイクロ秒 = 100 ミリ秒となり、1 vCPU が上限となる) |
| requests.memory | ・docker には渡されていない ・単純にコンテナ起動時に割り当て可能なリソースがあるかを見てるだけ |
| limits.memory | ・整数に変換された後に docker の --memory オプションとして使用される※ --memory はコンテナに割り当てるメモリ最大使用量(バイト)・例えば 512M を指定した場合、 --memory の値は(512 * 1024 * 1024 = )536870912 となる |
1.6. LimitRange
Pod やコンテナに対して、リソース制限のデフォルト値、最小、最大値等を制限できる LimitRange というリソースもあります。Namespace レベルで制限可能です。
設定できる項目と制限をかけられるリソースは以下です。
| 設定項目 | 制限をかけられるリソース |
|---|---|
| デフォルトの requests | コンテナ |
| デフォルトの limits | コンテナ |
| リソース使用量の最大値(最大の limits) | Pod,コンテナ,PersistentVolumeClaim |
| リソース使用量の最小値(最小の requests) | Pod,コンテナ,PersistentVolumeClaim |
| requests と limits の割合 | Pod,コンテナ |
LimitRange のユースケースは以下です。
- requests を指定しない場合は無限に Pod を起動しようとするので、デフォルトの requests を設定しておく事でその状況を防ぐ
- リソース使用量の最大値を設定することにより、過度なリソース使用を防ぐ
- requests と limits の割合を設定する事により、過度なオーバーコミットを防ぐ
1.7. QoS Class
Kubernetes は requests,limits に応じて Pod に QoS(Quality of Service)Class を割り当てます。 QoS Class には 3 種類あり、Kubernetes がコンテナの oom score を設定する際に使用されます。
| Class | 割り当てられる条件 | OOMKill される優先順位 |
|---|---|---|
| Guaranteed | Pod 内の全てのコンテナに CPU,メモリの requests,limits が設定されていて、requests と limits が同じ値 | 3 |
| Burstable | Guaranteed の条件を満たさない、かつ、Pod 内の一つ以上のコンテナに CPU,メモリの requests が設定されている | 2 |
| BestEffort | requests,limits 共に設定されていない | 1 |
Node のメモリ使用量が上限に達した場合には、まず BestEffort、次に Burstable、最後に Guaranteed のコンテナが kill されます。
1.8. ResourceQuota
Pod や Configmap,Service などの Kubernetes リソースの個数や使用量を制限できる ResourceQuota というリソースもあります。Namespace レベルで制限可能です。
CPU,メモリに関しては以下が設定可能です。
| パラメータ | 説明 |
|---|---|
| requests.cpu | 全 Pod の requests.cpu の合計 |
| limits.cpu | 全 Pod の limits.cpu の合計 |
| requests.memory | 全 Pod の requests.memory の合計 |
| limits.memory | 全 Pod の limits.memory の合計 |
リソースの個数も制限可能です。以下はその一部です。
| パラメータ | 説明 |
|---|---|
| count/pods | pod の数 |
| count/deployments | deployment の数 |
| count/services | service の数 |
| count/configmaps | configmap の数 |
2. 検証環境構築
2.1. EKS Cluster 構築
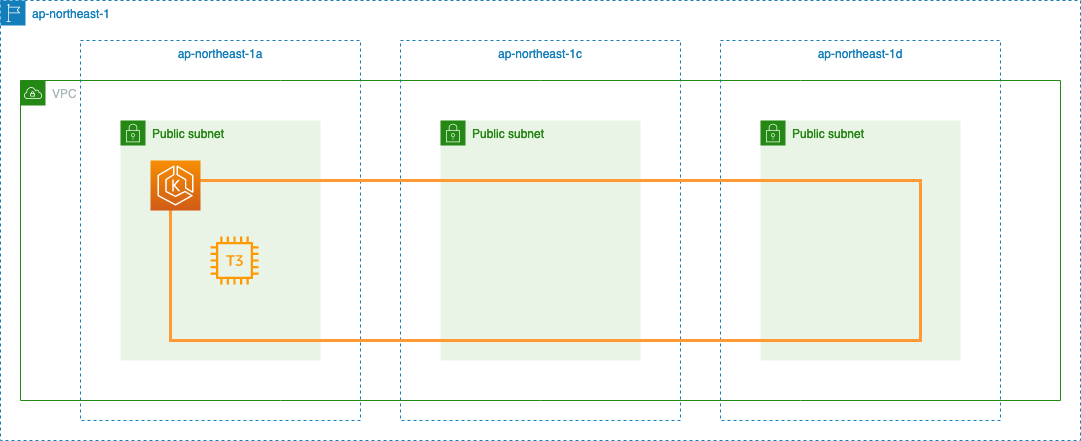
requests,limits の挙動を確認するため EKS 環境(Kubernetes のバージョンは 1.21)を構築します。
eksctl コマンドで EKS Cluster を作成する - YasuBlog の記事で作成した yaml を以下のように一部変更して Cluster を作成します。
--- apiVersion: eksctl.io/v1alpha5 kind: ClusterConfig metadata: name: ekstest region: ap-northeast-1 version: "1.21" vpc: id: "vpc-063b58ff16344acfd" subnets: public: ap-northeast-1a: id: "subnet-06324dcadf5706acb" ap-northeast-1c: id: "subnet-048cad38a6c49de67" ap-northeast-1d: id: "subnet-0bb85370bb4b4528d" managedNodeGroups: - name: managed-ng instanceType: t3.medium desiredCapacity: 1 volumeSize: 30 availabilityZones: ["ap-northeast-1a", "ap-northeast-1c", "ap-northeast-1d"] maxPodsPerNode: 20 ssh: allow: true publicKeyName: ekstest
以下構成の Cluster が作成されます。
2.2. Node のリソース量確認
初期構築後(デフォルトで起動する Pod 以外の Pod は起動していない状態)の Node のリソースの状態を確認します。 Node のインスタンスタイプは t3.micro のため、2vCPU、4GiB メモリのキャパシティがあります。
初期構築後の node describe コマンドの結果は以下です。
$ kubectl describe node ip-10-0-102-221.ap-northeast-1.compute.internal Name: ip-10-0-102-221.ap-northeast-1.compute.internal Roles: <none> Labels: alpha.eksctl.io/cluster-name=ekstest alpha.eksctl.io/nodegroup-name=managed-ng beta.kubernetes.io/arch=amd64 beta.kubernetes.io/instance-type=t3.medium beta.kubernetes.io/os=linux eks.amazonaws.com/capacityType=ON_DEMAND eks.amazonaws.com/nodegroup=managed-ng eks.amazonaws.com/nodegroup-image=ami-0c78e48568f9ea043 eks.amazonaws.com/sourceLaunchTemplateId=lt-0296f77bcc1eccc99 eks.amazonaws.com/sourceLaunchTemplateVersion=1 failure-domain.beta.kubernetes.io/region=ap-northeast-1 failure-domain.beta.kubernetes.io/zone=ap-northeast-1c kubernetes.io/arch=amd64 kubernetes.io/hostname=ip-10-0-102-221.ap-northeast-1.compute.internal kubernetes.io/os=linux node.kubernetes.io/instance-type=t3.medium topology.kubernetes.io/region=ap-northeast-1 topology.kubernetes.io/zone=ap-northeast-1c Annotations: node.alpha.kubernetes.io/ttl: 0 volumes.kubernetes.io/controller-managed-attach-detach: true CreationTimestamp: Sat, 06 Nov 2021 00:48:46 +0900 Taints: <none> Unschedulable: false Lease: HolderIdentity: ip-10-0-102-221.ap-northeast-1.compute.internal AcquireTime: <unset> RenewTime: Sat, 06 Nov 2021 01:38:30 +0900 Conditions: Type Status LastHeartbeatTime LastTransitionTime Reason Message ---- ------ ----------------- ------------------ ------ ------- MemoryPressure False Sat, 06 Nov 2021 01:34:30 +0900 Sat, 06 Nov 2021 00:48:46 +0900 KubeletHasSufficientMemory kubelet has sufficient memory available DiskPressure False Sat, 06 Nov 2021 01:34:30 +0900 Sat, 06 Nov 2021 00:48:46 +0900 KubeletHasNoDiskPressure kubelet has no disk pressure PIDPressure False Sat, 06 Nov 2021 01:34:30 +0900 Sat, 06 Nov 2021 00:48:46 +0900 KubeletHasSufficientPID kubelet has sufficient PID available Ready True Sat, 06 Nov 2021 01:34:30 +0900 Sat, 06 Nov 2021 00:49:06 +0900 KubeletReady kubelet is posting ready status Addresses: InternalIP: 10.0.102.221 ExternalIP: 54.238.138.51 Hostname: ip-10-0-102-221.ap-northeast-1.compute.internal InternalDNS: ip-10-0-102-221.ap-northeast-1.compute.internal Capacity: attachable-volumes-aws-ebs: 25 cpu: 2 ephemeral-storage: 31444972Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3967480Ki pods: 20 Allocatable: attachable-volumes-aws-ebs: 25 cpu: 1930m ephemeral-storage: 27905944324 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3412472Ki pods: 20 System Info: Machine ID: ec2589410cfceb731bf7e7a6679c9683 System UUID: ec258941-0cfc-eb73-1bf7-e7a6679c9683 Boot ID: a72aa7b5-a80b-4b01-b5c4-fc006aafb13d Kernel Version: 5.4.149-73.259.amzn2.x86_64 OS Image: Amazon Linux 2 Operating System: linux Architecture: amd64 Container Runtime Version: docker://20.10.7 Kubelet Version: v1.21.4-eks-033ce7e Kube-Proxy Version: v1.21.4-eks-033ce7e ProviderID: aws:///ap-northeast-1c/i-0cf593c64ada537b0 Non-terminated Pods: (4 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- kube-system aws-node-vqnj6 10m (0%) 0 (0%) 0 (0%) 0 (0%) 49m kube-system coredns-76f4967988-9wgqt 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 57m kube-system coredns-76f4967988-zcqwc 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 57m kube-system kube-proxy-gbjgl 100m (5%) 0 (0%) 0 (0%) 0 (0%) 49m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 310m (16%) 0 (0%) memory 140Mi (4%) 340Mi (10%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Starting 49m kubelet Starting kubelet. Normal NodeHasSufficientMemory 49m (x2 over 49m) kubelet Node ip-10-0-102-221.ap-northeast-1.compute.internal status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 49m (x2 over 49m) kubelet Node ip-10-0-102-221.ap-northeast-1.compute.internal status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID 49m (x2 over 49m) kubelet Node ip-10-0-102-221.ap-northeast-1.compute.internal status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 49m kubelet Updated Node Allocatable limit across pods Normal Starting 49m kube-proxy Starting kube-proxy. Normal NodeReady 49m kubelet Node ip-10-0-102-221.ap-northeast-1.compute.internal status is now: NodeReady
43 行目から 50 行目が Node としての Capacity(リソース総量)を表示しています。
CPU が 2、メモリが 3967480 KiB となっています。t3.medium 的にはメモリ量は 4GiB なので微妙に差がありますが、Node に SSH ログインして free でメモリ量を確認すると describe node 結果と同じ値になっています。
$ free
total used free shared buff/cache available
Mem: 3967480 409292 2092724 876 1465464 3353596
Swap: 0 0 0
ちなみに EC2 のスペックと OS から見えるメモリ量に差がある理由は以下に記載されています。
Q: オペレーティングシステムが報告するメモリ総量とインスタンスタイプの提供メモリが正確に一致しないのはなぜですか?
EC2 インスタンスメモリの一部は、ビデオ RAM、DMI、および ACPI のため、仮想 BIOS によって予約され使用されます。さらに、AWS Nitro Hypervisor を搭載したインスタンスでは、仮想化を管理するために、インスタンスメモリのごく一部が Amazon EC2 Nitro Hypervisor によって予約されます。
2.3. Pod に割り当て可能なリソース量確認
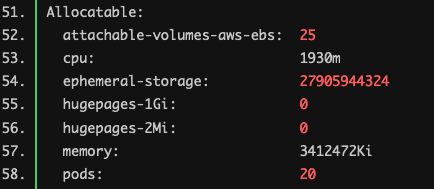
51 行目から 58 行目が Allocatable(Pod に割り当て可能なリソース量)を表示しています。
CPU が 1930m、メモリが 3412472 KiB となっています。 これは Node のキャパシティから (system-reserved + kube-reserved + eviction-threshold) を引いた値です。
ここらへんは別の記事で整理しますが、t3.medium の場合は以下のようになっています。
| system-reserved | kube-reserved | eviction-threshold | |
|---|---|---|---|
| CPU | 0 | 70m | 0 |
| メモリ | 0 | 442Mi | 100Mi |
そのため Allocatable は以下になり、describe node の結果と同じになります。
CPU = 2000 - 70 = 1930m
メモリ = 3967480 - (442 + 100) * 1024 = 3412472 KiB
なお、Allocatable はあくまでも Pod に割り当て可能なリソースの総量を表示しているため、Pod を新たに起動しても Allocatable は減りません。
2.4. Pod に割り当て済みのリソース量確認
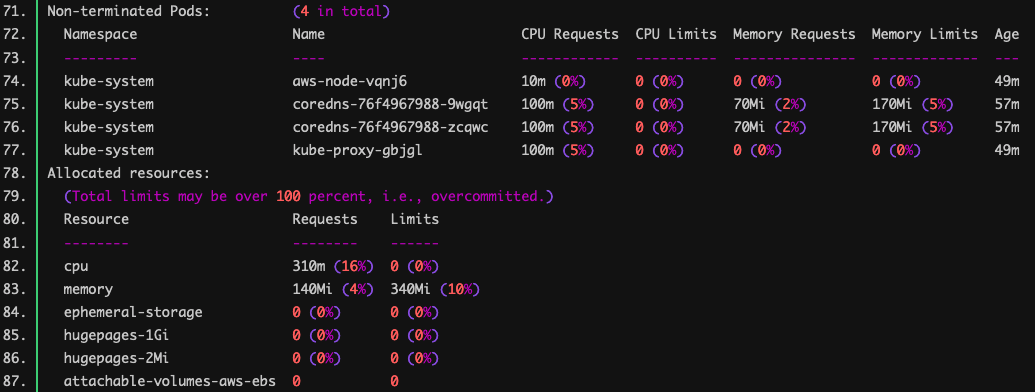
71 行目から 77 行目が Pod に割り当てたリソース、78 行目から 87 行目が割り当てたリソースのサマリを表示しています。
2.5. metrics-server インストール
Node や Pod の負荷を確認するのに便利な metrics-server というものをインストールします。手順は Kubernetes メトリクスサーバーのインストール - Amazon EKS に記載されている通りです。
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml serviceaccount/metrics-server created clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created clusterrole.rbac.authorization.k8s.io/system:metrics-server created rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created service/metrics-server created deployment.apps/metrics-server created apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created $ kubectl get deployment metrics-server -n kube-system NAME READY UP-TO-DATE AVAILABLE AGE metrics-server 1/1 1 1 3m48s
metrics-server を起動すると Node や Pod の負荷を kubectl top コマンドで確認できるようになります。
$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-101-50.ap-northeast-1.compute.internal 57m 2% 580Mi 17% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) test-deployment-d5d8f4656-b4gfp 0m 1Mi
3. 検証
3.1 requests,limits に指定した値が docker のオプションに使用されている事の確認
以下設定の deployment を起動して確認します。
| Kubernetes パラメータ | 値 |
|---|---|
| requests.cpu | 100m |
| limits.cpu | 200m |
| requests.memory | 64MB |
| limits.memory | 128MB |
manifest は以下です。
apiVersion: apps/v1 kind: Deployment metadata: name: test-deployment spec: replicas: 1 selector: matchLabels: app: test-app template: metadata: labels: app: test-app spec: containers: - name: amazonlinux image: public.ecr.aws/amazonlinux/amazonlinux:latest command: - "bin/bash" - "-c" - "sleep 3600" resources: requests: cpu: "100m" memory: "64M" limits: cpu: "200m" memory: "128M"
deployment 起動後に Node へ SSH ログインしてコンテナの情報を取得します。 dockder ps でコンテナ ID を確認し、docker inspect <コンテナ ID> で情報を取得できます。
$docker inspect c092f85463d0 | grep -i 'cpu\|memory' "CpuShares": 102, "Memory": 128000000, "NanoCpus": 0, "CpuPeriod": 100000, "CpuQuota": 20000, "CpuRealtimePeriod": 0, "CpuRealtimeRuntime": 0, "CpusetCpus": "", "CpusetMems": "", "KernelMemory": 0, "KernelMemoryTCP": 0, "MemoryReservation": 0, "MemorySwap": 128000000, "MemorySwappiness": null, "CpuCount": 0, "CpuPercent": 0,
requests,limits に設定した値と docker オプションに設定されている値を整理すると以下になります。
| Kubernetes パラメータ | 設定値 | docker へ渡す際の計算式 | docker オプション | 実際に設定されていた値 |
|---|---|---|---|---|
| requests.cpu | 100m | コア値に変換され 1024倍された値と 2 の大きい方が使われる100 / 1000 * 1024 = 102.4 |
--cpu-shares | 102 |
| limits.cpu | 200m | ミリコア値に変換され 100倍される200 * 100 = 20000 |
--cpu-quota | 20000 |
| requests.memory | 64M | (docker オプションに渡さない) | - | - |
| limits.memory | 128M | 整数に変換される128 * 1000 * 1000 = 128000000(MB を B に変換) |
--memory | 128000000 |
Kubernetes 側に設定したパラメータが実際に docker オプションに渡されている事が確認できました。
requests.cpu の「コア値に変換され 1024倍された値と 2 の大きい方が使われる」の確認のため、数パターンの requests,limits で試してみました。
| requests.cpu | --cpu-shares |
|---|---|
| 指定なし | 2 |
| 0 | 2 |
| 1m | 2 |
| 2m | 2 |
| 3m | 3 |
| 4m | 4 |
| 100m | 102 |
| 1000m | 1024 |
| limits.cpu | --cpu-quota |
|---|---|
| 指定なし | 0 |
| 0 | 0 |
| 1m | 1000 |
| 2m | 1000 |
| 3m | 1000 |
| 4m | 1000 |
| 10m | 1000 |
| 11m | 1100 |
| 12m | 1200 |
| 100m | 10000 |
| 1000m | 100000 |
| limits.memory | --memory |
|---|---|
| 指定なし | 0 |
| 0 | 0 |
| 8M | 8000000 |
| 16M | 16000000 |
| 1G | 1000000000 |
requests.cpu と limits.memory は想定通りでしたが、limits.cpu に関して、1m - 10m を指定した場合は --cpu-quota が 1000 になる事がわかりました。 (100 ミリ秒間に使用できる CPU 時間は 1000 マイクロ秒 = 1 ミリ秒となり、0.01 vCPU が上限となる)
3.2. requests
続いて、requests まわりの検証を実施します。作業前の describe node の結果は以下です。
$ kubectl describe node ~省略~ Capacity: attachable-volumes-aws-ebs: 25 cpu: 2 ephemeral-storage: 31444972Ki hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3967480Ki pods: 20 Allocatable: attachable-volumes-aws-ebs: 25 cpu: 1930m ephemeral-storage: 27905944324 hugepages-1Gi: 0 hugepages-2Mi: 0 memory: 3412472Ki pods: 20 ~省略~ Non-terminated Pods: (5 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- kube-system aws-node-drqbq 10m (0%) 0 (0%) 0 (0%) 0 (0%) 10h kube-system coredns-76f4967988-kdvr5 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 10h kube-system coredns-76f4967988-rf7fv 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 10h kube-system kube-proxy-lzz5r 100m (5%) 0 (0%) 0 (0%) 0 (0%) 10h kube-system metrics-server-7b9c4d7fd9-r6x5l 100m (5%) 0 (0%) 200Mi (6%) 0 (0%) 6m55s Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 410m (21%) 0 (0%) memory 340Mi (10%) 340Mi (10%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0
requests を設定して Pod を起動した際の Node の状態
以下設定の deployment で確認します。
resources: requests: cpu: "100m" memory: "64M"
deployment を起動します。
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
deployment 起動後の describe node の結果です。
$ kubectl describe node ~省略~ Non-terminated Pods: (6 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- default test-deployment-d5d8f4656-585d7 100m (5%) 0 (0%) 64M (1%) 0 (0%) 11s kube-system aws-node-drqbq 10m (0%) 0 (0%) 0 (0%) 0 (0%) 10h kube-system coredns-76f4967988-kdvr5 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 10h kube-system coredns-76f4967988-rf7fv 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 10h kube-system kube-proxy-lzz5r 100m (5%) 0 (0%) 0 (0%) 0 (0%) 10h kube-system metrics-server-7b9c4d7fd9-r6x5l 100m (5%) 0 (0%) 200Mi (6%) 0 (0%) 7m27s Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 510m (26%) 0 (0%) memory 420515840 (12%) 340Mi (10%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0
7 行目に新しく起動した Pod の情報が表示されています。 17,18 行目の Allocated(割り当て済みリソース)のサマリにも起動した Pod 分が加算されています。
requests を超えてリソースを使用できる
上記で作成した Pod に負荷をかけてみます。 まずは Pod にログインします。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-d5d8f4656-585d7 1/1 Running 0 41s $ kubectl exec -it test-deployment-d5d8f4656-585d7 -- /bin/bash
CPU 負荷をかけるため、定番の yes コマンドを Pod 内で実行します。
@pod$ yes > /dev/null
kubectl top コマンドで CPU 負荷を確認します。
## yes 実行前 $ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-101-50.ap-northeast-1.compute.internal 59m 3% 581Mi 17% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) test-deployment-d5d8f4656-585d7 0m 1Mi ## yes 実行中 $ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-101-50.ap-northeast-1.compute.internal 1049m 54% 582Mi 17% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) test-deployment-d5d8f4656-585d7 1001m 1Mi
15 行目の通り、Pod が requests の 100m を超えてリソースを使用できている事がわかります。(メモリも同様に requests を超過する事が可能です)
requests 分の空きが無い場合は Pod を起動できない
3 vCPU を Pod の requests.cpu に設定して確認します。(Node のキャパシティは 2 vCPU)
resources: requests: cpu: "3000m" memory: "64M"
deployment を起動します。
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
Pod の状態が Pending のまま変わりません。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-54657959ff-zzxlm 0/1 Pending 0 2m28s
describe pod の結果です。CPU が足りないためスケジューリングできていない事がわかります
$ kubectl describe pod test-deployment-54657959ff-zzxlm ~省略~ Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 60s (x4 over 3m15s) default-scheduler 0/1 nodes are available: 1 Insufficient cpu.
Node のメモリ上限に達すると Evict される
以下設定の deployment で確認します。
resources: requests: cpu: "100m" memory: "64M"
Pod が起動している事を確認します。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-d5d8f4656-6tdj7 1/1 Running 0 2m55s
kubectl top コマンドで Node と Pod のメモリ負荷を確認します。
$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-102-56.ap-northeast-1.compute.internal 57m 2% 565Mi 16% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) test-deployment-d5d8f4656-6tdj7 0m 0Mi
kubectl top だと実際のリソース使用量が反映されるまで少しタイムラグがあるため、今回は Node にログインして docker stats コマンドで Pod の負荷状況を確認します。
@node$ docker ps | grep amazonlinux 17709da044f5 public.ecr.aws/amazonlinux/amazonlinux "bin/bash -c 'sleep …" 11 minutes ago Up 11 minutes k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 @node$ while true; do docker stats 17709da044f5 --no-stream | tail -n1; sleep 2; done;
Pod にメモリ負荷をかけるため、Pod にログインして yes コマンドを実行します。一つでは足りないので複数実行します。
$ kubectl exec -it test-deployment-d5d8f4656-6tdj7 -- /bin/bash @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) &
docker stats の実行結果は以下のようになりました。
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 0.00% 844KiB / 3.784GiB 0.02% 0B / 0B 0B / 0B 1 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 0.00% 844KiB / 3.784GiB 0.02% 0B / 0B 0B / 0B 1 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 172.94% 45.49MiB / 3.784GiB 1.17% 0B / 0B 0B / 0B 8 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 196.51% 242.9MiB / 3.784GiB 6.27% 0B / 0B 0B / 0B 26 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 195.59% 438.9MiB / 3.784GiB 11.33% 0B / 0B 0B / 0B 26 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 190.47% 636.3MiB / 3.784GiB 16.42% 0B / 0B 0B / 0B 30 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 191.89% 829.1MiB / 3.784GiB 21.40% 0B / 0B 0B / 0B 31 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 196.63% 1.007GiB / 3.784GiB 26.61% 0B / 0B 0B / 0B 41 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 189.07% 1.2GiB / 3.784GiB 31.71% 0B / 0B 0B / 0B 51 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 194.21% 1.393GiB / 3.784GiB 36.81% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 186.31% 1.586GiB / 3.784GiB 41.92% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 189.37% 1.775GiB / 3.784GiB 46.92% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 193.21% 1.959GiB / 3.784GiB 51.78% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 184.15% 2.133GiB / 3.784GiB 56.36% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 194.42% 2.323GiB / 3.784GiB 61.40% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 196.99% 2.517GiB / 3.784GiB 66.51% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 186.78% 2.704GiB / 3.784GiB 71.47% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 191.34% 2.894GiB / 3.784GiB 76.50% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 193.25% 3.088GiB / 3.784GiB 81.61% 0B / 0B 0B / 0B 53 17709da044f5 k8s_amazonlinux_test-deployment-d5d8f4656-6tdj7_default_20f56f0e-f3d9-4e8d-87c5-3b2461bf742a_0 7.89% 3.099GiB / 3.784GiB 81.91% 0B / 0B 467MB / 0B 52 EOF Error response from daemon: No such container: 17709da044f5 Error response from daemon: No such container: 17709da044f5
メモリ使用量が 3GiB を超えたあたりでコンテナが消えました。 Pod の状況を確認します。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-d5d8f4656-6tdj7 0/1 Evicted 0 22m test-deployment-d5d8f4656-rpkwz 0/1 Pending 0 3m13s $ kubectl describe pod test-deployment-d5d8f4656-6tdj7 Name: test-deployment-d5d8f4656-6tdj7 Namespace: default Priority: 0 Node: ip-10-0-102-56.ap-northeast-1.compute.internal/ Start Time: Wed, 17 Nov 2021 23:07:18 +0900 Labels: app=test-app pod-template-hash=d5d8f4656 Annotations: kubernetes.io/psp: eks.privileged Status: Failed Reason: Evicted Message: The node was low on resource: memory. Container amazonlinux was using 3274620Ki, which exceeds its request of 64M. ~省略~ Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 22m default-scheduler Successfully assigned default/test-deployment-d5d8f4656-6tdj7 to ip-10-0-102-56.ap-northeast-1.compute.internal Normal Pulling 22m kubelet Pulling image "public.ecr.aws/amazonlinux/amazonlinux:latest" Normal Pulled 22m kubelet Successfully pulled image "public.ecr.aws/amazonlinux/amazonlinux:latest" in 10.601201753s Normal Created 22m kubelet Created container amazonlinux Normal Started 22m kubelet Started container amazonlinux Warning NodeNotReady 3m43s node-controller Node is not ready Warning Evicted 3m35s kubelet The node was low on resource: memory. Container amazonlinux was using 3274620Ki, which exceeds its request of 64M. Normal Killing 3m32s kubelet Stopping container amazonlinux
15,16 行目の通り、Node のリソースが不足したため Pod が Evict された事がわかります。
CPU リソースの奪い合いになった際の挙動
※メモリは Eviction Manager による Evict か OOMKiller により Kill されるため CPU のみ確認
requests.cpu が 200m の Pod(deployment)を二つ起動します。 最初に記載した通り requests.cpu は --cpu-shares に渡されます。--cpu-shares は CPU 割り当ての相対値のため今回のケースでは Pod A と B が使用できる CPU の比率は 1 対 1 となります。(A,B ともに 200m のため)
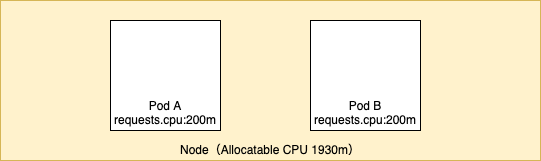
まずは Pod A に yes コマンドで限界まで CPU 負荷をかけてみます。
$ kubectl get pod NAME READY STATUS RESTARTS AGE deployment-a-6896bf676b-2wm6r 1/1 Running 0 13s deployment-b-567c479789-mk4wm 1/1 Running 0 9s $ kubectl exec -it deployment-a-6896bf676b-2wm6r -- /bin/bash @pod A$ yes > /dev/null & @pod A$ yes > /dev/null &
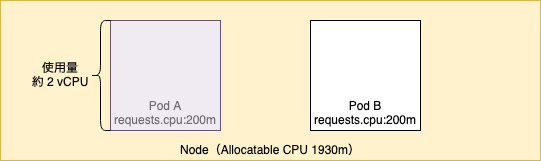
kubectl top で確認すると Pod A が 2vCPU を全て使っており、Pod B は全く使っていないことがわかります。
$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-101-93.ap-northeast-1.compute.internal 2004m 103% 581Mi 17% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) deployment-a-6896bf676b-2wm6r 1916m 1Mi deployment-b-567c479789-mk4wm 0m 0Mi
図に表すと以下のようになります。
この時に Pod B に同様に限界まで CPU を負荷をかけてみます。CPU 割り当て比率は 1 対 1 のため、Pod A の CPU 使用量が半減して Pod B が CPU を使えるはずです。
$ kubectl exec -it deployment-b-567c479789-mk4wm -- /bin/bash @pod B$ yes > /dev/null & @pod B$ yes > /dev/null &
kubectl top で確認すると Pod A と B の CPU 使用量が同じぐらいになりました。requests.cpu が相対値となっている事がわかります。
$ kubectl top node NAME CPU(cores) CPU% MEMORY(bytes) MEMORY% ip-10-0-101-93.ap-northeast-1.compute.internal 2007m 103% 578Mi 17% $ kubectl top pod NAME CPU(cores) MEMORY(bytes) deployment-a-6896bf676b-2wm6r 1011m 1Mi deployment-b-567c479789-mk4wm 974m 1Mi
図に表すと以下のようになります。
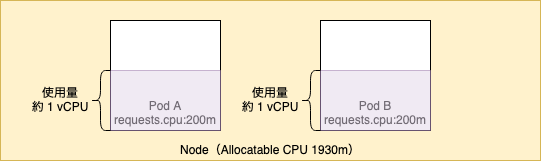
3.3. limits
続いて、limits まわりの検証を実施します。
limits を設定して Pod を起動した際の Node の状態
以下設定の deployment で確認します。
resources: requests: cpu: "100m" memory: "64M" limits: cpu: "200m" memory: "128M"
deployment を起動します。
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
deployment 起動後の describe node の結果です。
$ kubectl describe node ~省略~ Non-terminated Pods: (6 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- default test-deployment-75cff5888b-tbh5p 100m (5%) 200m (10%) 64M (1%) 128M (3%) 93s kube-system aws-node-j44fg 10m (0%) 0 (0%) 0 (0%) 0 (0%) 35m kube-system coredns-76f4967988-tczcz 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 50m kube-system coredns-76f4967988-ttpdm 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 50m kube-system kube-proxy-nkp2v 100m (5%) 0 (0%) 0 (0%) 0 (0%) 35m kube-system metrics-server-dbf765b9b-m2msv 100m (5%) 0 (0%) 200Mi (6%) 0 (0%) 23m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 510m (26%) 200m (10%) memory 420515840 (12%) 484515840 (13%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0
7 行目に新しく起動した Pod の情報が表示されています。requests だけでなく limits も表示されています。 17,18 行目の Allocated(割り当て済みリソース)のサマリにも起動した Pod 分が加算されています。
limits を超えてリソースを使用できない(CPU)
上記で作成した Pod に CPU 負荷をかけてみます。
リソース設定は以下の通り、200m が上限です。
resources: requests: cpu: "100m" memory: "64M" limits: cpu: "200m" memory: "128M"
Pod にログインして yes コマンドを実行します。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-75cff5888b-tbh5p 1/1 Running 0 109s $ kubectl exec -it test-deployment-75cff5888b-tbh5p -- /bin/bash @pod$ yes > /dev/null
Node にログインして docker stats で負荷を確認します。
@node$ while true; do docker stats fd0ba9708571 --no-stream | tail -n1; sleep 2; done; CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 0.00% 1.312MiB / 122.1MiB 1.08% 0B / 0B 65.5kB / 0B 2 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 0.00% 1.312MiB / 122.1MiB 1.08% 0B / 0B 65.5kB / 0B 2 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 0.00% 1.312MiB / 122.1MiB 1.08% 0B / 0B 65.5kB / 0B 2 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 21.56% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 20.99% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 19.69% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 22.36% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 21.33% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 20.24% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3 fd0ba9708571 k8s_amazonlinux_test-deployment-75cff5888b-tbh5p_default_effa950c-0594-42e2-92b8-aa957b064339_0 19.77% 1.562MiB / 122.1MiB 1.28% 0B / 0B 65.5kB / 0B 3
Pod の CPU 使用率の上限が 20%(200m コア)あたりになっており、limits を超えていない事がわかります。
limits を越えようとしても Pod は削除されずに起動し続けました。(メモリの場合とは挙動が異なります)
※docker stats の CPU % は 1 コアで 100% のため、20% の場合は 0.2 コア = 200m コアになる
limits を超えてリソースを使用できない(メモリ)
続いてメモリに負荷をかけます。
リソース設定は以下の通り、128MB が上限です。
resources: requests: cpu: "100m" memory: "64M" limits: cpu: "200m" memory: "128M"
Pod にログインして yes コマンドを実行します。
$ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-75cff5888b-hd8xz 1/1 Running 0 5m44s $ kubectl exec -it test-deployment-75cff5888b-hd8xz -- /bin/bash @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ /dev/null < $(yes) & @pod$ [1] Killed /dev/null < $(yes) @pod$ [2] Killed /dev/null < $(yes) @pod$ [3] Killed /dev/null < $(yes) @pod$ [4]- Killed /dev/null < $(yes) @pod$ [5]+ Killed /dev/null < $(yes)
yes コマンドが kill されました。Pod ごと Kill される想定でしたが違った結果になりました。
docker stats の結果です。
@node$ while true; do docker stats 505ae5eb47a6 --no-stream | tail -n1; sleep 2; done; CONTAINER ID NAME 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 720KiB / 122.1MiB 0.58% 0B / 0B 0B / 0B 1 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 1.281MiB / 122.1MiB 1.05% 0B / 0B 0B / 0B 2 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 19.42% 20.14MiB / 122.1MiB 16.50% 0B / 0B 0B / 0B 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 19.87% 41.03MiB / 122.1MiB 33.61% 0B / 0B 0B / 0B 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 20.21% 62.81MiB / 122.1MiB 51.46% 0B / 0B 0B / 0B 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 20.91% 83.11MiB / 122.1MiB 68.09% 0B / 0B 0B / 0B 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 19.87% 104.1MiB / 122.1MiB 85.30% 0B / 0B 0B / 0B 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 77.51% 92.06MiB / 122.1MiB 75.41% 0B / 0B 0B / 90.6kB 12 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 37.26% 65.62MiB / 122.1MiB 53.75% 0B / 0B 0B / 90.6kB 11 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 14.88% 23.12MiB / 122.1MiB 18.94% 0B / 0B 0B / 90.6kB 9 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 1.547MiB / 122.1MiB 1.27% 0B / 0B 0B / 90.6kB 7 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 1.547MiB / 122.1MiB 1.27% 0B / 0B 0B / 90.6kB 7 505ae5eb47a6 k8s_amazonlinux_test-deployment-75cff5888b-hd8xz_default_cf5d282d-f128-44f9-9586-0eace273c69a_0 0.00% 1.547MiB / 122.1MiB 1.27% 0B / 0B 0B / 90.6kB 7
100 MB を超えたあたりでメモリ使用量が下がってます。このタイミングで yes が kill されています。
Pod の状態を確認します。
$ kubectl describe pod test-deployment-75cff5888b-hd8xz
~省略~
Containers:
amazonlinux:
Container ID: docker://505ae5eb47a638015f612b6b364b3984e73bfde35c187b252aa18719d706c6e7
Image: public.ecr.aws/amazonlinux/amazonlinux:latest
Image ID: docker-pullable://public.ecr.aws/amazonlinux/amazonlinux@sha256:916dbbb288948b54c94b5b9f0769085aa601d4468d099e90d8a7da5cfa551b50
Port: <none>
Host Port: <none>
Command:
bin/bash
-c
sleep 3600
State: Running
State が Running になっており kill されていません。OOM Killer によってコンテナのプロセスではなく負荷コマンド yes のプロセスが kill されたためです。
想定挙動とは異なる結果となったため、今度はコンテナ起動時に負荷コマンドを実行してみます。(コンテナのプロセスそのものが負荷をかけている状態にする)
負荷テスト用の polinux/stress イメージを使って 128MB 上限の Pod に 256MB の負荷をかけます。
apiVersion: apps/v1 kind: Deployment metadata: name: test-deployment spec: replicas: 1 selector: matchLabels: app: test-app template: metadata: labels: app: test-app spec: containers: - name: memory-test image: polinux/stress resources: requests: memory: "64M" limits: memory: "128M" command: ["stress"] args: ["--vm", "1", "--vm-bytes", "256M", "--vm-hang", "1"]
$ kubectl apply -f test-deployment.yaml deployment.apps/test-deployment created $ kubectl get pod -w NAME READY STATUS RESTARTS AGE test-deployment-f5784d6f4-rbrfb 0/1 ContainerCreating 0 2s test-deployment-f5784d6f4-rbrfb 1/1 Running 0 3s test-deployment-f5784d6f4-rbrfb 0/1 OOMKilled 0 4s test-deployment-f5784d6f4-rbrfb 1/1 Running 1 6s test-deployment-f5784d6f4-rbrfb 0/1 OOMKilled 1 7s test-deployment-f5784d6f4-rbrfb 0/1 CrashLoopBackOff 1 8s test-deployment-f5784d6f4-rbrfb 0/1 OOMKilled 2 22s test-deployment-f5784d6f4-rbrfb 0/1 CrashLoopBackOff 2 34s test-deployment-f5784d6f4-rbrfb 0/1 OOMKilled 3 49s
Running になった直後に OOMKilled 状態になりました。 describe の結果からも OOMKiller によって kill された事がわかります。
$ kubeclt describe pod test-deployment-f5784d6f4-rbrfb
~省略~
Containers:
memory-test:
Container ID: docker://05c9e3436ea39469706baab7996ce056b152a3be3fe8aebc31ca9c4d07d15072
Image: polinux/stress
Image ID: docker-pullable://polinux/stress@sha256:b6144f84f9c15dac80deb48d3a646b55c7043ab1d83ea0a697c09097aaad21aa
Port: <none>
Host Port: <none>
Command:
stress
Args:
--vm
1
--vm-bytes
256M
--vm-hang
1
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: OOMKilled
Exit Code: 1
Started: Thu, 18 Nov 2021 00:18:02 +0900
Finished: Thu, 18 Nov 2021 00:18:03 +0900
Ready: False
Restart Count: 3
※ OOM score まわりについては別記事で整理します
limits 分の空きが無い場合でも Pod を起動できる
3 vCPU を Pod の limits.cpu に設定して確認します。(Node のキャパシティは 2 vCPU)
resources: requests: cpu: "100m" memory: "64M" limits: cpu: "3000m" memory: "64M"
エラーなく Pod を起動できます。
$ kubectl apply -f test-deployment.yaml deployment.apps/test-deployment created $ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-9f4c9f997-zgngg 1/1 Running 0 7s
describe node の結果は以下です。17 行目の通り limits に 100% を超えた値が設定されています。
$ kubectl describe node ~省略~ Non-terminated Pods: (6 in total) Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age --------- ---- ------------ ---------- --------------- ------------- --- default test-deployment-9f4c9f997-zgngg 100m (5%) 3 (155%) 64M (1%) 128M (3%) 48s kube-system aws-node-j44fg 10m (0%) 0 (0%) 0 (0%) 0 (0%) 151m kube-system coredns-76f4967988-tczcz 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 166m kube-system coredns-76f4967988-ttpdm 100m (5%) 0 (0%) 70Mi (2%) 170Mi (5%) 166m kube-system kube-proxy-nkp2v 100m (5%) 0 (0%) 0 (0%) 0 (0%) 151m kube-system metrics-server-dbf765b9b-m2msv 100m (5%) 0 (0%) 200Mi (6%) 0 (0%) 139m Allocated resources: (Total limits may be over 100 percent, i.e., overcommitted.) Resource Requests Limits -------- -------- ------ cpu 510m (26%) 3 (155%) memory 420515840 (12%) 484515840 (13%) ephemeral-storage 0 (0%) 0 (0%) hugepages-1Gi 0 (0%) 0 (0%) hugepages-2Mi 0 (0%) 0 (0%) attachable-volumes-aws-ebs 0 0
requests に何も設定しない場合は limits と同じ値が requests に設定される
以下設定の deployment で確認します。
resources: limits: cpu: "200m" memory: "128M"
Pod を起動します。
$ kubectl apply -f test-deployment.yaml deployment.apps/test-deployment configured $ kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-6f5f85d8d4-hn5f9 1/1 Running 0 33s
describe pod の結果です。
$ kubectl describe pod test-deployment-6f5f85d8d4-hn5f9
~省略~
State: Running
Started: Thu, 18 Nov 2021 01:39:51 +0900
Ready: True
Restart Count: 0
Limits:
cpu: 200m
memory: 128M
Requests:
cpu: 200m
memory: 128M
11-13 行目の通り、requests に limits と同じ値が設定されています。
3.4. LimitRange
デフォルトの requests,limits を設定
コンテナに対してデフォルトの requests.cpu を 250m、limits.cpu を 500m に設定した LimitRange(limitrange.yaml)を作成します。
apiVersion: v1 kind: LimitRange metadata: name: cpu-limit-range spec: limits: - default: cpu: 500m defaultRequest: cpu: 250m type: Container
apply します。
$ kubectl apply -f limitrange.yaml limitrange/cpu-limit-range created $ kubectl get limitrange NAME CREATED AT cpu-limit-range 2021-11-19T13:26:17Z $ kubectl describe limitrange Name: cpu-limit-range Namespace: default Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Container cpu - - 250m 500m -
requests.cpu,limits.cpu を指定していない Pod を起動します。
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
describe pod を確認すると、LimitsRange で指定した requests.cpu と limits.cpu が Pod に設定されている事がわかります。
$ kubectl describe pod
~省略~
State: Running
Started: Fri, 19 Nov 2021 22:27:23 +0900
Ready: True
Restart Count: 0
Limits:
cpu: 500m
Requests:
cpu: 250m
ちなみに limitrange を削除した後に Pod を再起動(delete pod 実行後に deployment により新しい Pod が起動)したところ requests,limits は設定されていませんでした。
リソース使用量の最小値、最大値を設定
メモリの最小使用量を 64MB、最大使用量を 128MB に設定した LimitRange を作成します。
apiVersion: v1 kind: LimitRange metadata: name: memory-max spec: limits: - min: memory: 64M max: memory: 128M type: Container
apply します。
$ kubectl apply -f limitrange.yaml limitrange/memory-max created $ kubectl get limitrange NAME CREATED AT memory-max 2021-11-19T13:33:06Z $ kubectl describe limitrange Name: memory-max Namespace: default Type Resource Min Max Default Request Default Limit Max Limit/Request Ratio ---- -------- --- --- --------------- ------------- ----------------------- Container memory 64M 128M 128M 128M -
最小値、最大値だけでなくデフォルトの requests,limits も設定されました。 これは、デフォルトの requests,limits を指定しない場合は最大値に指定した値が設定されるためです。
256MB のメモリを使用する Pod を起動します。
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
$ kubectl describe pod
~省略~
Limits:
memory: 128M
Requests:
memory: 128M
LimitRange の最大値に指定した値(128M)が Pod の limits に設定されるため、256M を使用する Pod は OOMKilled になり再起動を繰り返す状態になりました。
$ kubectl get pod -w NAME READY STATUS RESTARTS AGE test-deployment-889b488cd-gf7mx 0/1 Pending 0 0s test-deployment-889b488cd-gf7mx 0/1 ContainerCreating 0 0s test-deployment-889b488cd-gf7mx 0/1 OOMKilled 0 3s test-deployment-889b488cd-gf7mx 1/1 Running 1 5s test-deployment-889b488cd-gf7mx 0/1 OOMKilled 1 6s test-deployment-889b488cd-gf7mx 0/1 CrashLoopBackOff 1 7s test-deployment-889b488cd-gf7mx 1/1 Running 2 24s test-deployment-889b488cd-gf7mx 0/1 OOMKilled 2 25s
3.5. QoS Class
requests,limits が CPU,メモリともに設定されていて requests と limits が同じ値となる Pod を起動します。(Guaranteed の条件)
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
$ kubectl describe pod
~省略~
QoS Class: Guaranteed
QoS Class が Guaranteed になっています。
requests,limits が異なる Pod を起動します。(Burstable の条件)
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
$ kubectl describe pod
~省略~
QoS Class: Burstable
QoS Class が Burstable になっています。
requests,limits を指定しない Pod を起動します。(BestEffort の条件)
$ kubectl apply -f test-deployment.yaml
deployment.apps/test-deployment created
$ kubectl describe pod
~省略~
QoS Class: BestEffort
QoS Class が BestEffort になっています。
3.6. ResourceQuota
全 Pod の requests.cpu の合計を 1 に設定する ResourceQuota(resourcequota.yaml)を作成します。
apiVersion: v1 kind: ResourceQuota metadata: name: compute-resources spec: hard: requests.cpu: "1"
apply します。
$ kubectl apply -f resoucequota.yaml resourcequota/compute-resources created $ kubectl get resourcequota NAME AGE REQUEST LIMIT compute-resources 31s requests.cpu: 0/1 $ kubectl describe resourcequota Name: compute-resources Namespace: default Resource Used Hard -------- ---- ---- requests.cpu 0 1
requests.cpu が 200m の Pod を 10 個起動する deployment を起動してみます。
$ kubectl apply -f test-deployment5.yaml deployment.apps/test-deployment created $kubectl get pod NAME READY STATUS RESTARTS AGE test-deployment-8d58b6999-7j9cl 1/1 Running 0 10s test-deployment-8d58b6999-7rx82 1/1 Running 0 10s test-deployment-8d58b6999-9cpvk 1/1 Running 0 10s test-deployment-8d58b6999-swk4v 1/1 Running 0 10s test-deployment-8d58b6999-z2xww 1/1 Running 0 10s $ kubectl get deploy NAME READY UP-TO-DATE AVAILABLE AGE test-deployment 5/10 5 5 52s
Pod が ResourceQuota で設定した 5 個までしか起動できていない事がわかります。
4. 所管
かなり長くなってしまった。Kubernetes は考えなきゃいけない事が多いですね。
5. 参考
Reserve Compute Resources for System Daemons | Kubernetes
PodにQuality of Serviceを設定する | Kubernetes
community/resource-qos.md at master · kubernetes/community · GitHub
Node-pressure Eviction | Kubernetes
Pod Priority and Preemption | Kubernetes
Configure Default CPU Requests and Limits for a Namespace | Kubernetes